TCP Segment Offload for DPDK vRouter
Vrouter does Tx and Rx TCP segmentation offload in the kernel mode currently. It largely leverages kernel APIs for achieving this. However, wrt DPDK, the library lacks segmentation support/API’s and hence DPDK based vrouter cannot do the offloads. For achieving line rate performance of TCP based workloads on 10G NIC’s, we need DPDK based vrouter to support offloads.
TCP based workloads greatly benefit when segmentation/reassembly of TCP segments are done by the lower most layers like MAC layer or the NIC itself. In case of Tx, the application can send large sized TCP segments of upto 64K to the TCP stack, which transparently passes them to the lowers layers of the stack. The segmentation is generally done in the MAC layer, which adds the remaining headers like IP/TCP to each MSS sized payload and sends it to the NIC. In some cases NIC itself can do all these instead of the MAC layer. The overhead of header addition and packet processing for these smaller MSS sized packets by all layers of TCP/IP stack is avoided and there-by boosts the performance. Likewise, for Rx, the NIC or MAC layer can assemble the smaller MSS sized segments and form a larger sized segment before handing it over to the IP layer there-by avoiding processing of headers at each layer of the networking stack.
Terminology wise, when the NIC does the segmentation, it is called TCP send offload (TSO)/TCP receive offload (TRO) and when segmentation is done in software, it is called Generic send offload (GSO)/Generic Receive offload (GRO).
In case of virtualized environments, offload further improves VMExits which result due to the avoidance of large number of packet exchanges between the host and guest.
The figure below compared GSO with no-GSO. For GRO, the operation will be similar, but in the other direction.
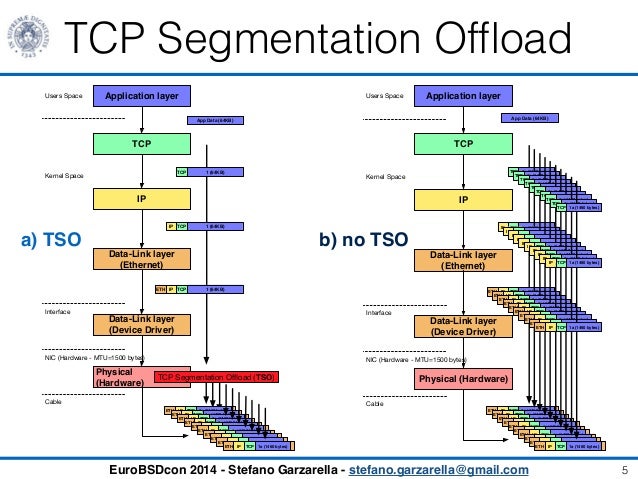
None. This feature is enabled by default if the VM supports it
Setup
=> Intel E5-2463 v3 Haswell CPU running @ 3.40 GHz
=> 2 sockets @ 6 cores/socket
=> L1 cache 64K, L2 cache 256K, L3 cache 20M
=> DIMM RAM 256Gb, channels 8
=> 2-port Intel 82599 NIC non-bonded
=> Hyper-threading enabled
------------------------------------------------------
| | Throughput | VM Exits | Cache Misses |
|-------------------------------------------------------
|No-GRO | | | |
|GRO | | | |
|No-GSO | | | |
|GSO | | | |
------------------------------------------------------