

generate2vivo is an extensible Data Ingest and Transformation Tool for the open source software VIVO. It currently contains queries for metadata from Datacite Commons, Crossref, ROR and ORCID and maps them to the VIVO ontology using sparql-generate. The resulting RDF data can be exported to a VIVO instance (or any SPARQL endpoint) directly or it can be returned in JSON-LD.
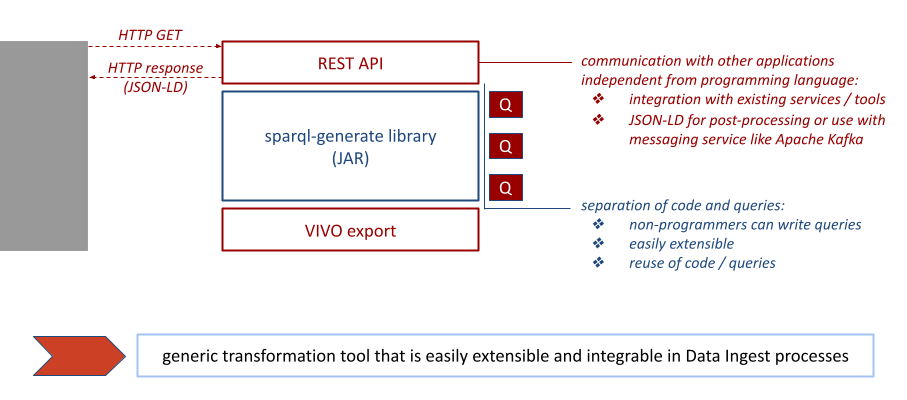
Starting point was the sparql-generate library that we use as an engine for our transformations, which are defined in different GENERATE queries. Notice that code and queries are separate, this allows users
- to write or change queries without going into the code
- to reuse queries (meaning you can dump the code and only use the queries for example with the command line tool provided on the sparql-generate website)
- to reuse code (meaning you can dump the queries if the data sources are not interesting for you and use only the code with your own queries)
In addition we gave the application a REST API so other programs or services can communicate with the application using HTTP requests which allows generate2vivo to be integrated in an existing data ingest process.
On the other side we added output functionality that allows you to export the generated data either directly into a VIVO instance via its SPARQL API or alternatively if you want to check the data before importing or are using a messaging service like Apache Kafka you can return the generated data as JSON-LD and do some post-processing with it.
- Prerequisites: You need to have maven and a JDK for Java 11 installed.
- Clone the repository to a local folder using
git clone https://github.com/vivo-community/generate2vivo.git - Change into the folder where the repository has been cloned.
- Open
src/main/resources/application.propertiesand change your VIVO details accordingly. If you don't provide a vivo.url, vivo.email or vivo.password, the application will not import the mapped data to VIVO but return the triples in format JSON-LD. - Run the application:
- You can run the application directly via
mvn spring-boot:run. - Or alternatively you can run the application in Docker:
mvn spring-boot:build-image docker run -p 9000:9000 generate2vivo:latest
- A minimal swagger-ui will be available at
http://localhost:9000/swagger-ui/.
Additional resources are available in the GitHub wiki, e.g.
-
data sources & queries : A detailed overview of the data sources and their queries.
-
using generate2vivo: A short user tutorial with screenshots on how to use the swagger-UI to execute a query.
-
run queries in cmd line : An alternative way of running the queries via cmd line with the provided Jar from sparql-generate.
-
dev guide : resources specifically for developers, e.g. on how to add a data source or query, how to put variables from code into the query.