![]()

The goal of hemibrainr is to provide useful code for preprocessing and analysing data from the Janelia FlyEM hemibrain project. It makes use of the natverse R package, neuprintr to get hemibrain data from their connectome analysis and data hosting service neuprint. The dataset has been described here. Using this R package in concert with the natverse ecosystem is highly recommended.
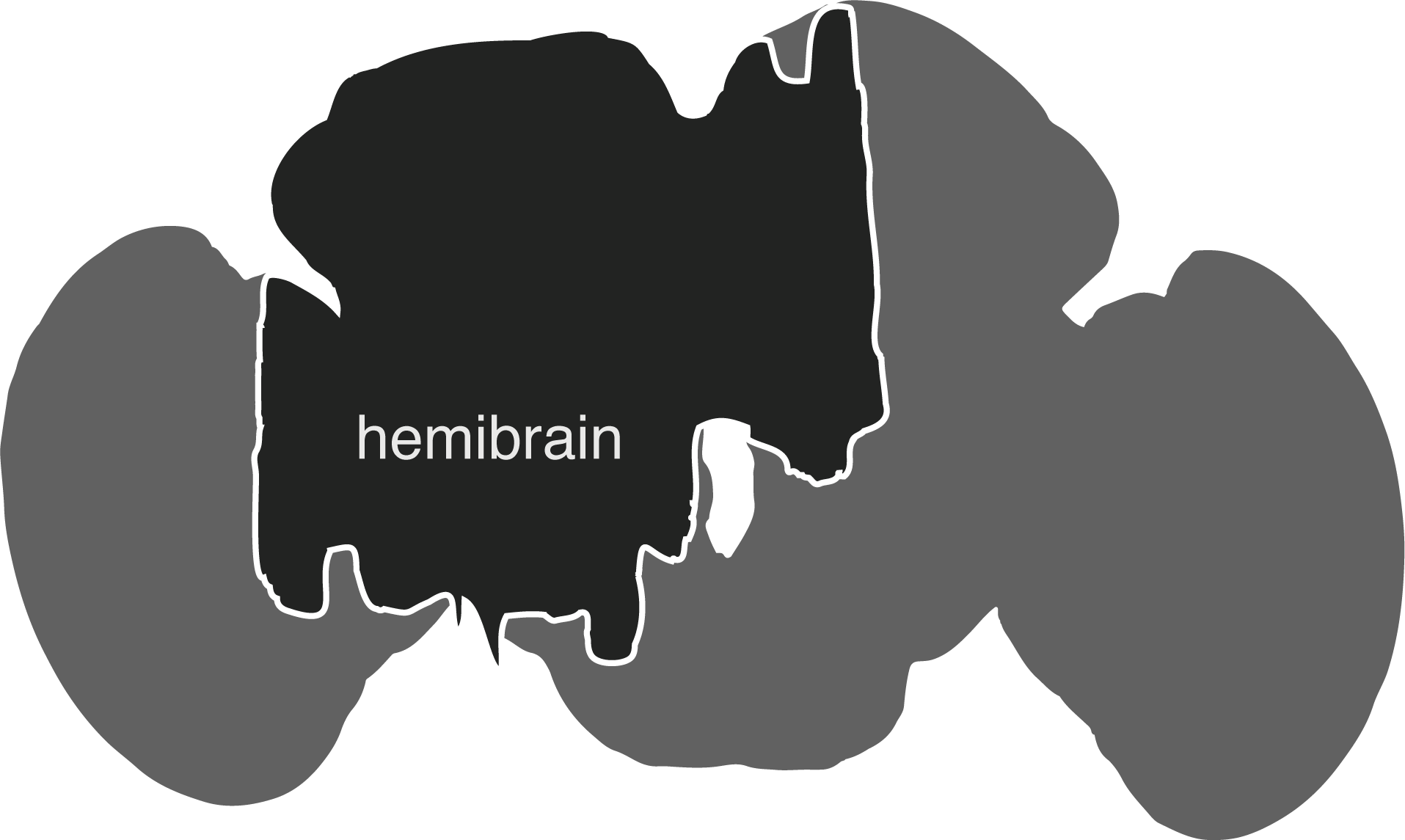
The hemibrain connectome comprises the region of the fly brain depicted below. It is ~21,662 ~full neurons, 9.5 million synapses and is about ~35% complete in this region:
# install
if (!require("remotes")) install.packages("remotes")
remotes::install_github("natverse/hemibrainr")
# use
library(hemibrainr)hemibrainr contains tools with which to quickly work with hemibrain and FlyWire neurons, and match up neurons within and between data sets.
If you can connect to the hemibrainr google shared drive, this package puts thousands of hemibrain and FlyWire neurons at your fingertips, as well as information on their compartments (e.g. axons versus dendrites), synapses and connectivity and between data set neuron-neuron matches. You can:
- Read thousands of pre-skeletonised FlyWire/hemibrain neurons from Google Drive
- Read FlyWire/hemibrain NBLASTs and NBLASTs to hemibrain neurons
- Read FlyWire/hemibrain neurons that are pre-transformed into a variety of brainspaces
Which is all useful stuff. You can explore our articles for more detailed information on what the package can do, and how to set it up with the data stored on Google drive - but can take a quick tour here:
# Load package
library(hemibrainr)
# Else, it wants to see it on the mounted team drive, here
options("Gdrive_hemibrain_data")
# We can load meta data for all neurons in hemibrain
db = hemibrain_neurons()
# And quickly read them from the drive, when we try to plot/analyse them!
hemibrain_view()
plot3d(hemibrain.surf, col = "grey", alpha = 0.1)
plot3d(db[1:10])See which neurons have been matched up:
# See matches, you can do this without hemibrain Google Team Drive access
View(hemibrain_matched)
# Get fresh matches, you cannot do this without access
## You will be prompted to log-in through your browser
hemibrain_matched_new <- hemibrain_matches()
## NOTE: includes hemibrain<->FlyWire matches!In order to use neuprintr, which fetches data we want to use with hemibrainr, you will need to be able to login to a neuPrint server and be able to access it underlying Neo4j database.
You may need an authenticated accounted, or you may be able to register
your @gmail address without an authentication process. Navigate to a
neuPrint website, e.g. https://neuprint.janelia.org, and hit ‘login’.
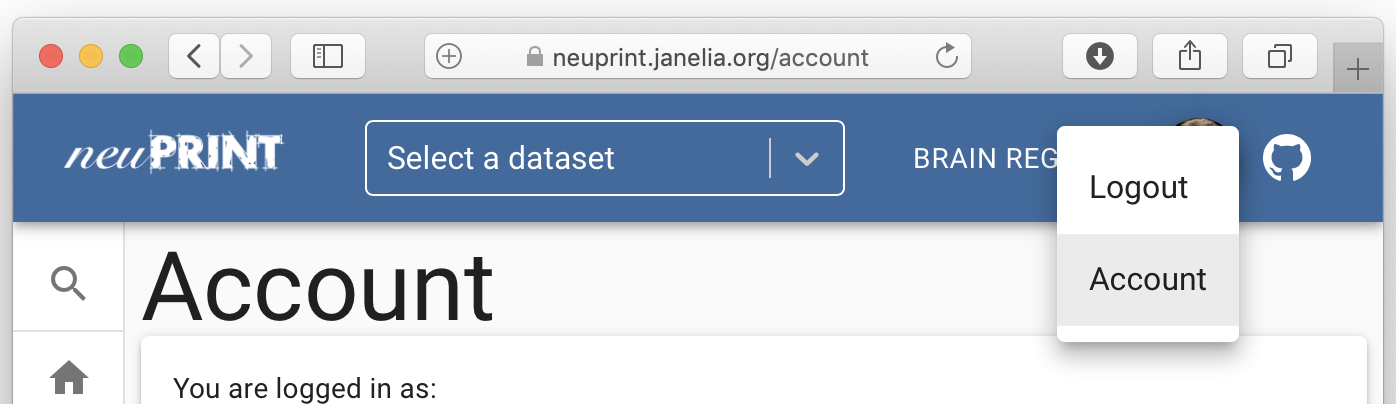
Sign in using an @gmail account. If you have authentication/the server
is public, you will now be able to see your access token by going to
‘Account’:
To make life easier, you can then edit your .Renviron file to contain
information about the neuPrint server you want to speak with, your token
and the dataset hosted by that server, that you want to read. A
convenient way to do this is to do
usethis::edit_r_environ()and then edit the file that pops up, adding a section like
neuprint_server="https://neuprint.janelia.org"
# nb this token is a dummy
neuprint_token="asBatEsiOIJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJlbWFpbCI6ImIsImxldmVsIjoicmVhZHdyaXRlIiwiaW1hZ2UtdXJsIjoiaHR0cHM7Ly9saDQuZ29vZ2xldXNlcmNvbnRlbnQuY29tLy1QeFVrTFZtbHdmcy9BQUFBQUFBQUFBDD9BQUFBQUFBQUFBQS9BQ0hpM3JleFZMeEI4Nl9FT1asb0dyMnV0QjJBcFJSZlI6MTczMjc1MjU2HH0.jhh1nMDBPl5A1HYKcszXM518NZeAhZG9jKy3hzVOWEU"Make sure you have a blank line at the end of your .Renviron file. For
further information try about neuprintr login, see the help for
neuprint_login().
Finally you can also login on the command line once per session, like so:
conn = neuprintr::neuprint_login(server= "https://neuprint.janelia.org/",
token= "asBatEsiOIJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJlbWFpbCI6ImIsImxldmVsIjoicmVhZHdyaXRlIiwiaW1hZ2UtdXJsIjoiaHR0cHM7Ly9saDQuZ29vZ2xldXNlcmNvbnRlbnQuY29tLy1QeFVrTFZtbHdmcy9BQUFBQUFBQUFBDD9BQUFBQUFBQUFBQS9BQ0hpM3JleFZMeEI4Nl9FT1asb0dyMnV0QjJBcFJSZlI6MTczMjc1MjU2HH0.jhh1nMDBPl5A1HYKcszXM518NZeAhZG9jKy3hzVOWEU")This is also the approach that you would take if you were working with more than two neuPrint servers.
For this, you need access to th hemibrainr google team drive. Authentication is through an email account. Once you have access, there are two basic ways to mount the data for use:
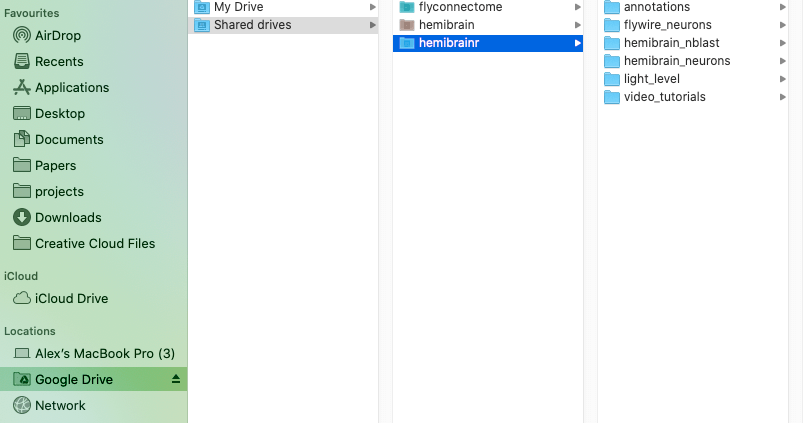
Option 1, mount your Google drives using Google filestream. However, for this to work you will need Google Workspace, Google’s monthly subscription offering for businesses and organizations. One the Google filestream application is run, you should be able to see your drives mounted like external hard drive, as so:
{kind=link}
Then, this should work:
# Set a new Google drive, can be the team drive name or a path to the correct drive
hemibrainr_set_drive("hemibrainr") # No need to run this each time though, this is the default. Use if you want to use a different name drive.
# Now just get the name of your default team drive.
## This will be used to locate your team drive using the R package googledrive
hemibrainr_team_drive()Option 2, this is free. You still need authenticated access to the hemibrainr Gogle team drive. It can then be mounted using rclone. First, download rclone for your operating system. You can also download from your system’s command line (e.g. from terminal) and then configure it for the drive:
# unix/macosx
curl https://rclone.org/install.sh | sudo bash
rclone configAnd now check this has worked:
# mounts in working directory
hemibrainr_rclone()
# Now hemibrain neurons are read from this mount
db = hemibrain_neurons() # read from the google drive
length(db)
plot3d(hemibrain_neurons[1:10])
# Specifically, from here
options("Gdrive_hemibrain_data")
# unmounts
hemibrainr_rclone_unmount()
# And now we are back to:
options("Gdrive_hemibrain_data")For more detailed instructions, see this article.
Let’s get started with a useful function for splitting a neuron into its axon and dendrite:
# Choose neurons
## These neurons are some 'tough' examples from the hemibrain:v1.0.1
### They will split differently depending on the parameters you use.
tough = c("5813056323", "579912201", "5813015982", "973765182", "885788485",
"915451074", "5813032740", "1006854683", "5813013913", "5813020138",
"853726809", "916828438", "5813078494", "420956527", "486116439",
"573329873", "5813010494", "5813040095", "514396940", "665747387",
"793702856", "451644891", "482002701", "391631218", "390948259",
"390948580", "452677169", "511262901", "422311625", "451987038"
)
# Get neurons
neurons = neuprint_read_neurons(tough)
# Now make sure the neurons have a soma marked
## Some hemibrain neurons do not, as the soma was chopped off
neurons.checked = hemibrain_skeleton_check(neurons, meshes = hemibrain.rois)
# Split neuron
## These are the recommended parameters for hemibrain neurons
neurons.flow = flow_centrality(neurons.checked, polypre = TRUE,
mode = "centrifugal",
split = "distance")
# Plot the split to check it
nat::nopen3d()
nlscan_split(neurons.flow, WithConnectors = TRUE)- HemiBrain (hemibrain:v1.0) : from “A Connectome of the Adult Drosophila Central Brain” (Xu, et al. 2020)
neuPrint comprises a set of tools for loading and analyzing connectome data into a Neo4j database. Analyze and explore connectome data stored in Neo4j using the neuPrint ecosystem: neuPrintHTTP, neuPrintExplorer, Python API.
This package was created by Alexander Shakeel Bates and Gregory Jefferis. You can cite this package as:
citation(package = "hemibrainr")Bates AS, Jefferis GSXE (2020). hemibrainr: Code for working with data from Janelia FlyEM’s hemibrain project. R package version 0.1.0. https://github.com/natverse/hemibrainr