{kind=link}
{kind=link}
A fully functional Othello game, with several AIs, made for the swi prolog interpreter

This app allows 2 players to play an Othello game.
During de pre-game menu the admin can set the two players to human or AIs.
-- Set the Player x to be a --
1. Human---> User input. prompt.pl
2. Bot (random)---> A totally random AI. random.pl
3. Bot (minmax)---> An AI using the min-max algorithm. minmax.pl
4. Bot (alphabeta)---> An AI using the alpha-beta algorithm. alphabeta.pl
Load the file in the swipl-interpreter:
$ swipl ./othello.pl
Play the game:
>?- play.
I used this excellent heuristic/evaluation function, made by researchers from the University of Washington.
This heuristic function is actually a collection of several heuristics and calculates the utility value of a board position by assigning different weights to those heuristics here.
The heuristic takes into account:
To ensure the best performance and to improve the bot playing time the Game Engine use a cache.pl system.
The Cache saves the Heuristic value of a given board. here.
This method saves (roughly):
- 20000 call out of 36000 when running a AlphaBeta of Depth 4 (-1min30 save on my machine 2min10 vs 3min40).
- 66000 call out of 77000 when running a MinMax of Depth 4 (-9min save on my machine 11min vs 20min).
The Cache is also used to save some computing time of the next board generation witch in his own cut the number of call to this rule by half (20 seconds save).
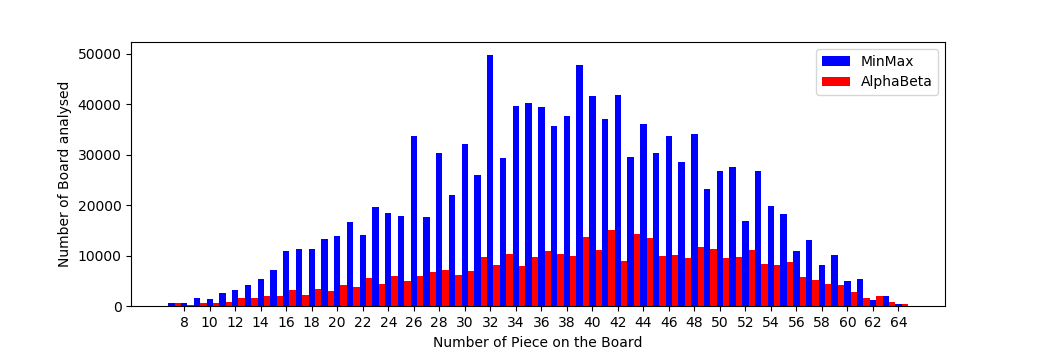
Note that the overall trend in counts analyzed by Min-Max increases in the first third following a Gaussian strongly pronounced. This is because the board is free, and many combinations are allowed. In the next 2 thirds, the descent is also done according to the distribution of gauss, since the number of game combinations decreases gradually as we reach the edges.
In depth 6 we have 3.8 million board
analyzed, to play an obvious shot find in depth 2.
Evidence appears: Alpha-Beta is still not the reincarnation of pure optimization
...
I always write the test of the rule/predicate, below and indented by 3 tabs of the definition of itself.
1. +/-inf heuristic when wining/losing. (some plays are more rewards than a winning one..)
2. Dynamic stability_weights - The stability_weights penalize the player making a move on a adjacent corners cell. But if the same player own the related corner it's actualy not a bad move..
3. Dynamic weights in the dynamic_heuristic_evaluation
- At the start we need to reduce the opponent mobility
- In the middle game we need to focus on the stability of your placement
- In the very end of the game we only focus on the coin parity
4. Remove the ugly if/then/else
5. Make use of board symmetrys to improve the Cache systems
6. GnuProlog (2x faster)