{kind=link}
{kind=link}
The Iowa Gambling Task(IGT) is a test for Orbitofrontal Cortex (OFC) dysfunction patients. The project aims to find dominant patterns for each patient by applying PCA, and determine the characteristics of patients with and without OCR.
The characteristics are then plotted, to find out the clusters and correlation between test score and OCR prevalence. The final step is to find out typical patterns (decreasing order of occurence) as below.
The data used is gathered from the studies of Fernie & Tunney (2006), Fridberg et al. (2010), Kjome et al. (2010), Premkumar et al. (2008), Rodriguez-Sanchez et al. (2005), Toplak et al. (2005), Wood et al. (2005) and Steingroever et al (2013) (All based on a standardized IGT)
- Participants are presented with four decks of cards.
- They are told that each deck holds cards that will either reward or penalize them, using real money(for the listed studies below).
- The goal of the game is to win as much money as possible. The decks differ in the balance of reward versus penalty cards. Some decks are "bad decks", and others are "good decks".
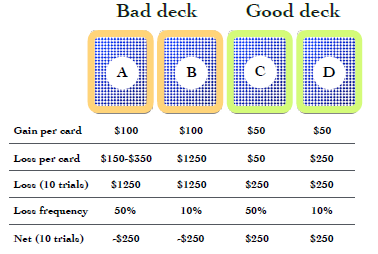
Most healthy participants are fairly good at sticking to the good decks, after about 50 selections. Patients with OFC dysfunction, continue to persevere with bad decks, sometimes even if they know that they are losing money.
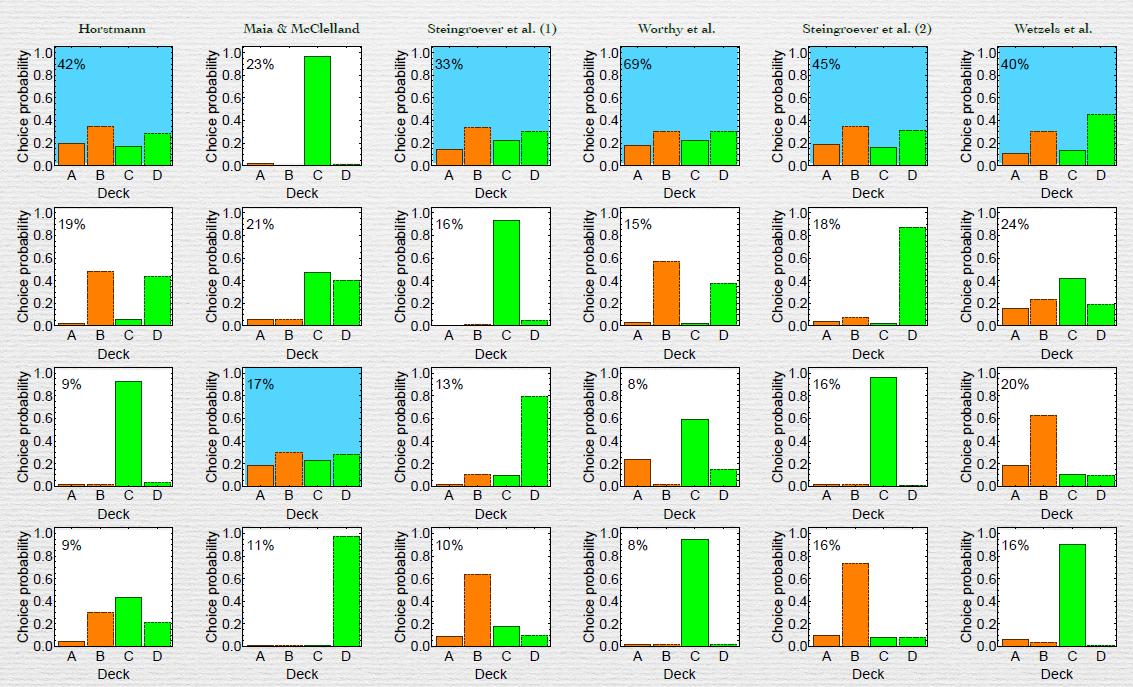
Clustering Analysis of all available research data on the IGT(list of sources in readme) using R. The Scripts produce the output for the most common archetypes among the dataset of one researcher using PCA.
The data contains the series data of upto a 100 card choices for each patient, and associated knowlegde on the presence of dysfunction.
Through Clustering Analysis, the typical patterns for the frequency of choices of cards are output as below.Each column is for the data of a different study. The scripts provided processes only Steingrover's data(can be changed on the first few lines of code).