Maria Guideng
😴 Oh hi. This repo is no longer maintained. Go here for the gdscrapeR package instead. 👻
Scrape Glassdoor.com for company reviews. Prep text data for text analytics.
Take Tesla for example. The url to scrape will be: https://www.glassdoor.com/Reviews/Tesla-Reviews-E43129.htm
Here's a screen shot of the text to extract:
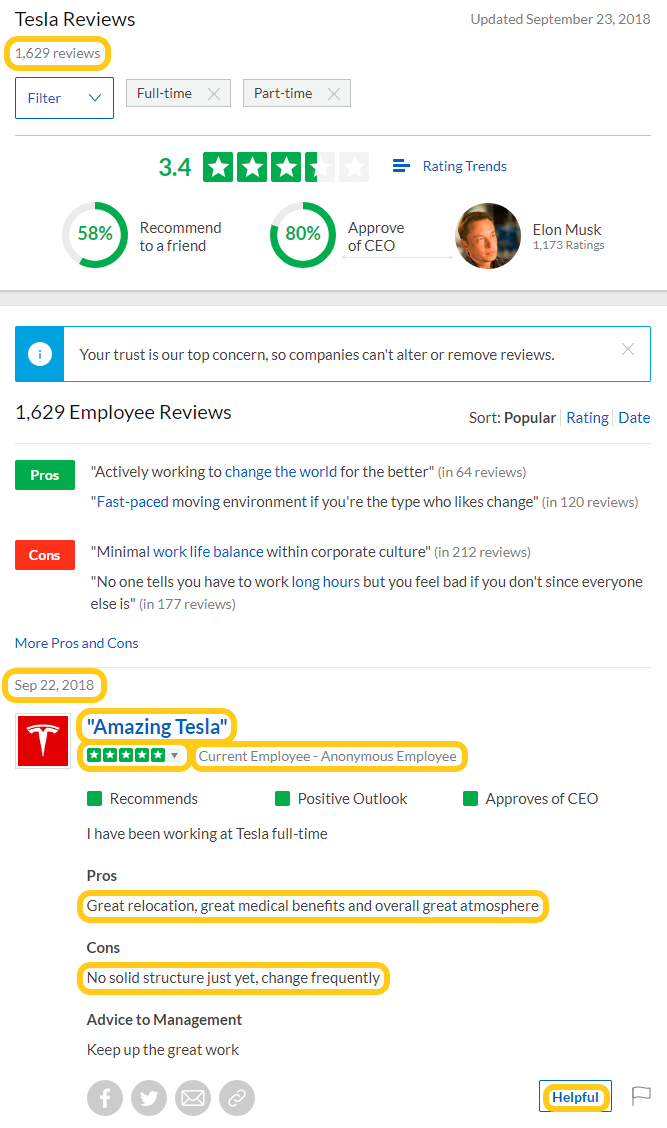
Web scraper function
Extract company reviews for the following:
- Total reviews - by full & part-time workers only
- Date - of when review was posted
- Summary - e.g., "Amazing Tesla"
- Rating - star rating between 1.0 and 5.0
- Title - e.g., "Current Employee - Anonymous Employee"
- Pros - upsides of the workplace
- Cons - downsides of the workplace
- Helpful - number marked as being helpful, if any
#### SCRAPE ####
# Packages
library(rvest) #scrape
library(purrr) #iterate scraping by map_df()
# Set URL
baseurl <- "https://www.glassdoor.com/Reviews/"
company <- "Tesla-Reviews-E43129"
sort <- ".htm?sort.sortType=RD&sort.ascending=true"
# How many total number of reviews? It will determine the maximum page results to iterate over.
totalreviews <- read_html(paste(baseurl, company, sort, sep="")) %>%
html_nodes(".margBot.minor") %>%
html_text() %>%
sub(" reviews", "", .) %>%
sub(",", "", .) %>%
as.integer()
maxresults <- as.integer(ceiling(totalreviews/10)) #10 reviews per page, round up to whole number
# Scraping function to create dataframe of: Date, Summary, Rating, Title, Pros, Cons, Helpful
df <- map_df(1:maxresults, function(i) {
Sys.sleep(sample(seq(1, 5, by=0.01), 1)) #be a polite bot. ~12 mins to run with this system sleeper
cat("boom! ") #progress indicator
pg <- read_html(paste(baseurl, company, "_P", i, sort, sep="")) #pagination (_P1 to _P163)
data.frame(rev.date = html_text(html_nodes(pg, ".date.subtle.small, .featuredFlag")),
rev.sum = html_text(html_nodes(pg, ".reviewLink .summary:not([class*='hidden'])")),
rev.rating = html_attr(html_nodes(pg, ".gdStars.gdRatings.sm .rating .value-title"), "title"),
rev.title = html_text(html_nodes(pg, "#ReviewsFeed .hideHH")),
rev.pros = html_text(html_nodes(pg, "#ReviewsFeed .pros:not([class*='hidden'])")),
rev.cons = html_text(html_nodes(pg, "#ReviewsFeed .cons:not([class*='hidden'])")),
rev.helpf = html_text(html_nodes(pg, ".tight")),
stringsAsFactors=F)
})RegEx
Use regular expressions to clean and extract additonal variables:
- Reviewer ID (1 to N reviewers by date, sorted from first to last)
- Year (from Date)
- Location (e.g., Palo Alto, CA)
- Position (e.g., Project Manager)
- Status (current or former employee)
#### REGEX ####
# Packages
library(stringr) #pattern matching functions
# Clean: Helpful
df$rev.helpf <- as.numeric(gsub("\\D", "", df$rev.helpf))
# Add: ID
df$rev.id <- as.numeric(rownames(df))
# Extract: Year, Position, Location, Status
df$rev.year <- as.numeric(sub(".*, ","", df$rev.date))
df$rev.pos <- sub(".* Employee - ", "", df$rev.title)
df$rev.pos <- sub(" in .*", "", df$rev.pos)
df$rev.loc <- sub(".*\\ in ", "", df$rev.title)
df$rev.loc <- ifelse(df$rev.loc %in%
(grep("Former Employee|Current Employee", df$rev.loc, value = T)),
"Not Given", df$rev.loc)
df$rev.stat <- str_extract(df$rev.title, ".* Employee -")
df$rev.stat <- sub(" Employee -", "", df$rev.stat)Output
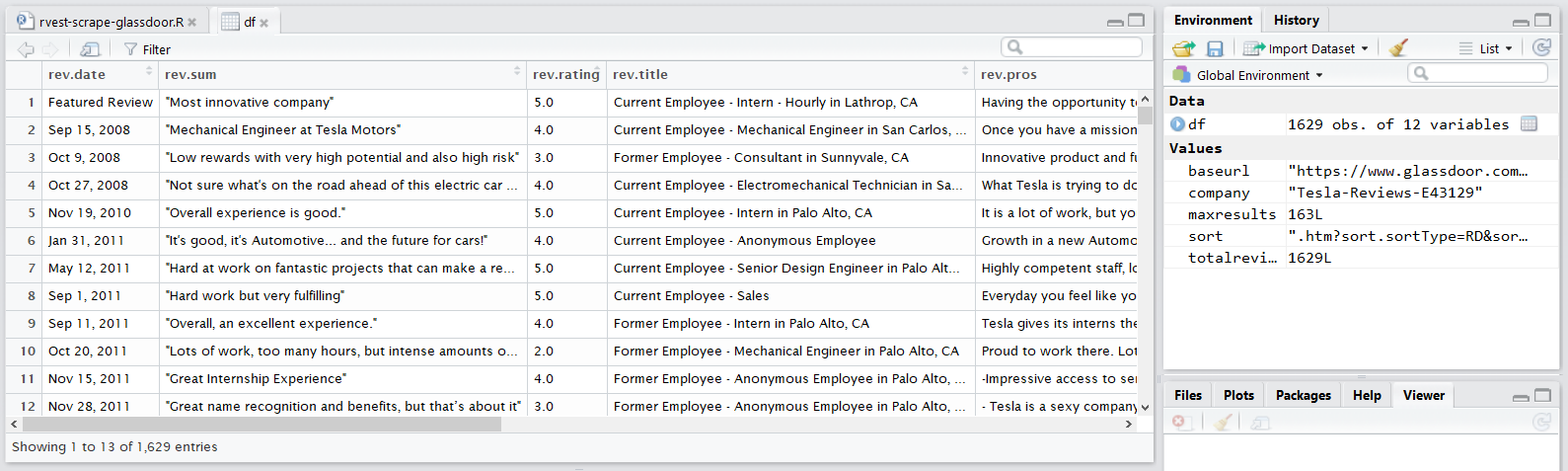
#### EXPORT ####
write.csv(df, "rvest-scrape-glassdoor-output.csv") #to csvNotes
- Write up of demo: "Scrape Glassdoor Company Reviews in R Using the gdscraper Package".
- Updated 9/23/2018 to add star "rating" field. Initial commit 8/1/2018.