The repository contains the code set for the project for course ILS Z534 Information Retrieval offered during Fall 2014. The project had two tasks as explained below:
Categorize the business based on the review text. Idea was to follow Machine Learning Approach and use Multinomial Naive Bayes Classification algorithm as this is a multi label classification problem. Library used for this task was Weka Library.
Here, we use Bag-of-words model and Naive Bayes Algorithm assumes all the words are independent of each other. The features are the set of words which were chosen using TF-IDF and labels are the set of categories. The evaluation metrics used for this task is Precision and Recall. Root Mean Square Error was used to calculate the amount of deviation in predicting the categories. The training to test data set ratio was 80:20.
Worked on a data set that contained every unique business id with corresponding categories of Restaurants that belong to it and every review associated with that id. Followed the Machine Learning Approach and used Multinomial Naive Bayes Classification algorithm as this is a multi label classification problem. Library used for this task was Weka Library.
The features are the set of words which were chosen using TF-IDF and labels are the set of categories. The evaluation metrics used for this task is Precision and Recall. Root Mean Square Error was used to calculate the amount of deviation in predicting the categories. The training to test data set ratio was k fold cross validation with a factor of 5 across the data set.
| Algorithm/Metric | Accuracy | Average Precision | Average Recall |
|---|---|---|---|
| Multinomial Naive Bayes | 35.35% | 0.33 | 0.353 |
| Naive Bayes | 32.34% | 0.34 | 0.323 |
| SMO (SVM using Poly Kernel) | 30.41% | 0.294 | 0.304 |
| Decision Trees | 27.41% | 0.266 | 0.274 |
Try to predict the review rating from the review text. We try couple of approaches:
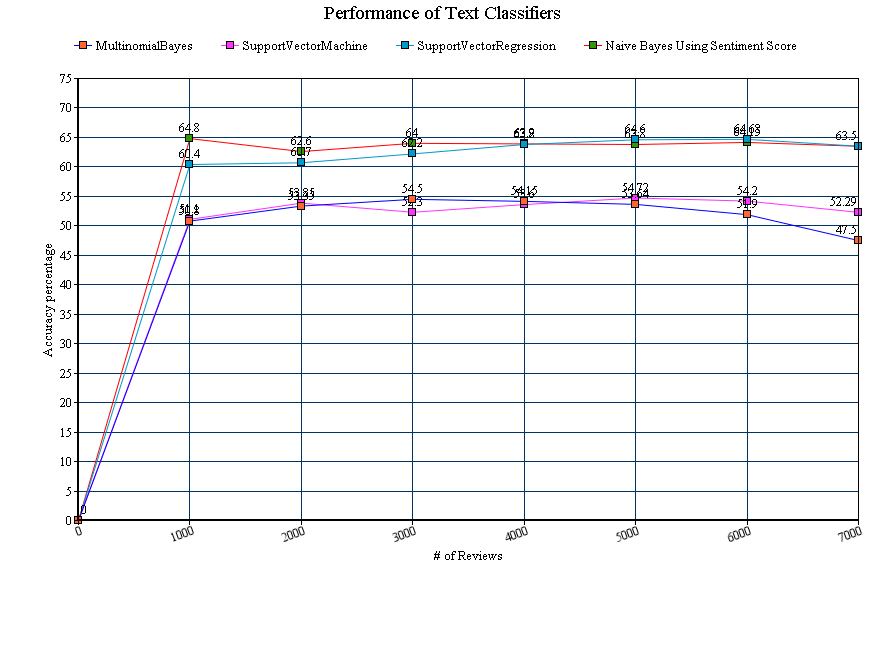
- Under Supervised Learning, we use Multinomial Bayes, Support Vector Machine and Support Vector Regression algorithms to classify the text based on the reviews. These algorithms are available as part of SciKit python library.
- Next approach under Supervised Learning, was to use NaiveBayesAnalyzer which is available as part of TextBlob python library. TextBlob library is built on top of NLTK. The NaiveBayesAnalyzer is trained using 1000 positive movie reviews and 1000 negative reviews. It was surprising to see that accuracy was more when we used the model based on movie reviews.
- The last approach is a kind of un-supervised learning approach where we try to use SentiWordNet and Stanford NLP. Stanford NLP is used for POS tagging. Once the text is tagged, SentiWordNet is used to get the sentiment score based on the POS and the word. We then choose the top 20 words based on the sentiment score and come up with the sentiment of the text. Based on this sentiment score, the review is categorized into ratings from 1 to 5.