Research and showcase optimal technology stack and procedures to build publicly accessible database and data mining toolkit. Learn more between funds as an ecosystem by analyzing all the available data and finding out what works and what doesn't. Test and verify with existing datasets, learn through network analysis, clustering algorithms and natural language processing. Opportunities and risks from generative AI for community roles in the assessment and supervision of proposals.

Data-driven predictions can succeed - and they can fail. It is when we deny our role in the process that the odds of failure rise. Before we demand more of our data, we need to demand more of ourselves.
Nate Silver
This binder has five distinct sections:
- The Roadmap of this project - its parts and planned delivery dates
- Overview of the Open Source Data Science (OSDS ecosystem and stack and how this can bring cutting edge machine learning, data visualization and artificial intelligence applications to everyone thanks to permissive licenses and easy, low-code modules.
- Overview of how Project Catalyst generates data and can be understood and improved with data science, and how this has changed over the funds and is likely or desirable to evolve in the future.
- Working with fund data takes the theoretical and introductory outline of Catalyst data to concrete applications and examples and works through demonstrations that are either particularly elegant or of didactic value, or have been requested by the community and stakeholders as part of this project.
- Using AI expands the data science definition to more recent, more sophisticated applications like Large Language Models (LLMs) and other AI to showcase how human community reviewers, supervisors and voters can benefit from AI augmentation, conversational data discovery or unsupervised prompts. This includes a discussion of limitations and risks of AI as well.
On the Github repository there are a further three folders for Code, Funds data and Workshop footage and minutes.
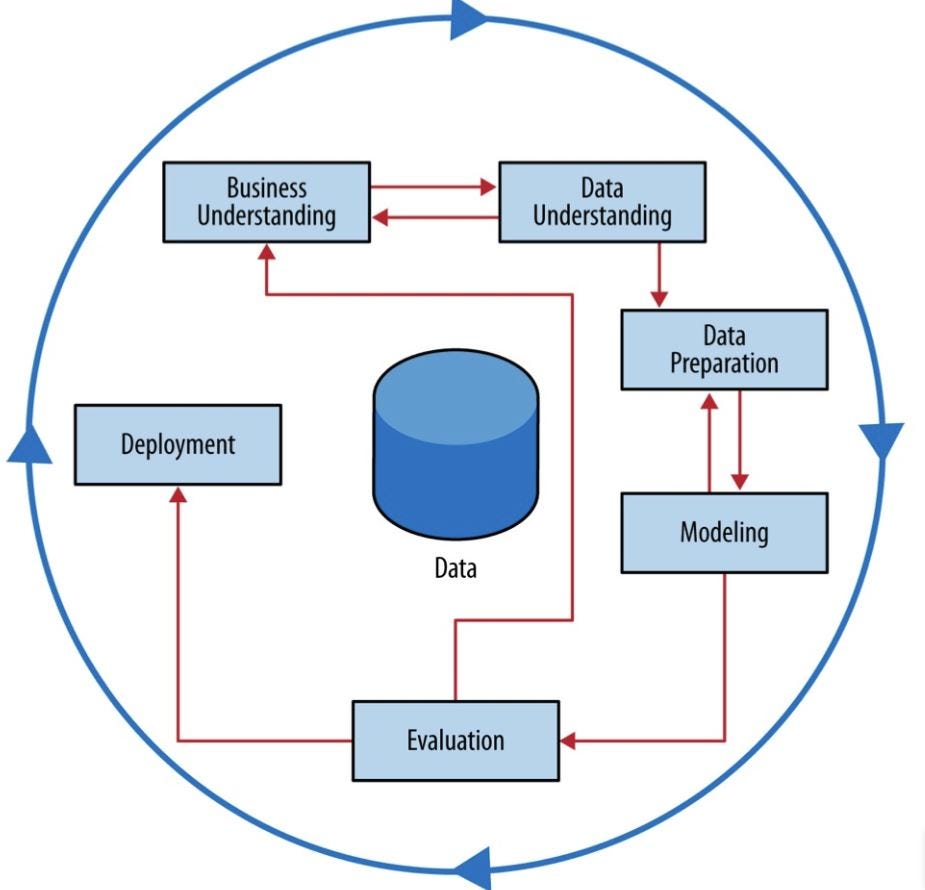
For data mining and data science, "garbage in, garbage out" is an important caveat to keep in mind. With new methods to gather, store and process big data, ingenuity and creativity are required to discover new sources of data. In financial markets, credit card data and satellite images of parking lots and harbors can be used to gain insights into economic activity and financial performance long before economic data or financial reporting releases. The same is true for Catalyst data, where sources like on-chain voting, Lido Nation, even Twitter and Telegram chats or Github commits could be queried for deep understanding. But do we have the right tools to crawl and clean the data? Can formats like PNG or propritary formats be converted to easily yield data structures open source tools can understand? This is an exciting new world with countless possibilities, but not every idea is feasible and not all data is created equal. We look forward to community input for ideas how to improve Catalyst with data that are both actionable, meaning findings can inform better behavior or optimized procedures, and feasible, meaning the processing work required is proportionate to the value of the results.
No data platform is complete without a suitable database, for example Cloud SQL, and at least a lightweight API to allow other apps to interact with its data. Stack discussion for this is crucial but depends on other stakeholders and will be discussed at a more advanced stage when we have gathered enough feedback what kind of analysis the community wants to see and what is most suited to help improve Project Catalyst going forward.
A note on external references: Where possible, we link sources directly as hyperlinks, linked images etc. instead of footnotes, as this in our opinion works better for Github/Gitbook formats.
Data Mining Workflow