DefaultCPUAllocator: not enough memory #4
Comments
|
the model keeps the pre-processed data into memory, I don't think decreasing the batch size will help. |
|
I restart pre-processed.py, and run run_models.py I got Finished loading dataset! Epoch-0Training: 0it [00:00, ?it/s]Traceback (most recent call last): Is that my pytorch version's problem? my pytorch version is 1.1.0 |
|
no, looks like you are running it on cpu, did you use the argument for running it on the gpu? |
|
yes, I try it again and it show i cheak my CUDA and CUDNN, and their version is 9.1 & 7.1.2 |
|
maybe check your pytorch gpu configuration/version properly with this? In [2]: torch.cuda.current_device() In [3]: torch.cuda.device(0) |
|
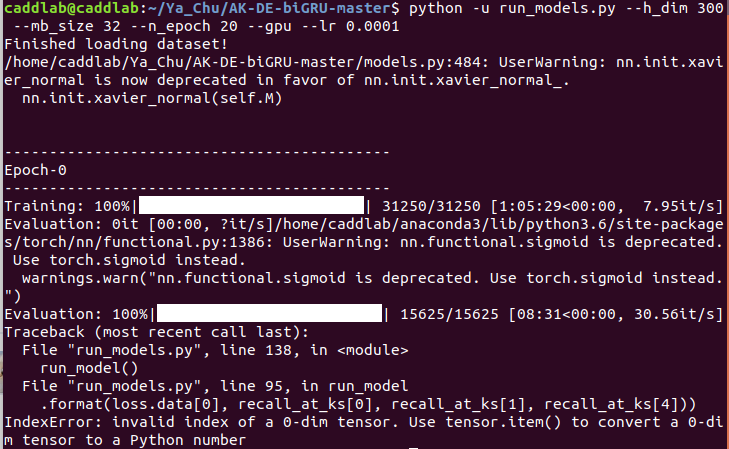
I finally run success ,but when i run finish it show that
how should I solve it ? |
|
cool that you could run it. |
|
thanks very much |
|
provide the model with a question utterance and a set of possible response, the output would be a predicted response. |
|
should I run something when I provide the model with a question utterance? |
|
I don't have anything readymade. You need to reuse parts from the batcher (data) and run_models to get the predictions. |
I tried to python python -u run_models.py --h_dim 300 --mb_size 32 --n_epoch 20 --gpu --lr 0.0001 till i got
RuntimeError: [enforce fail at ..\c10\core\CPUAllocator.cpp:62] data. DefaultCPUAllocator: not enough memory: you tried to allocate %dGB. Buy new RAM!208096001
I have 48GB of RAM and a 1060 GPU (6GB), is is not enough?
how should i do?
thanks
The text was updated successfully, but these errors were encountered: